

TGV Lyria
How TGV Lyria Turned CRM Data Into a Scalable, Deliverability-Safe Campaign Machine
From messy lists to a clean, compliant CRM backbone for high-speed rail.
4 350
duplicate contacts merged
367
duplicate companies merged
159,000 contacts
migrated from Sarbacane to HubSpot, then Brevo
The Challenge: Migrate Fast, Break Nothing
The brief to Cashmyrr was clear:
Execute a fast, reliable migration from Sarbacane to Brevo without losing data quality or usability, ideally improving both.
Move to the right tool stack for high-volume communication and TGV Lyria’s existing contact base.
Fully integrate large-group constraints: cybersecurity, GDPR, and internal approval workflows from SNCF and CFF.
Behind that brief were some very real pain points.
The existing setup was fragmented, with three key blocks in scope:
Legacy emailing tool: Sarbacane
CRM / data core: HubSpot
Transactional & marketing email platform: Brevo
Source data was spread across flat CSV/Excel lists, split by language (FR, DE, EN), with opt-ins stored as "Oui", "Ja", "1" and other variants. Years of imports and manual handling had also mixed in:
complaints
NPAI (“N’habite Pas à l’Adresse Indiquée” postal returns / invalid addresses)
unsubscribes inside the same lists as active contacts
Bounce, a lot of them that wasn't defined
On top of that, a big-company context (SNCF / CFF) brought extra layers of cybersecurity, GDPR documentation, and internal validation workflows. The main risks were clear:
losing the ability to send mass communications
degrading email deliverability
making internal workflows heavier instead of simpler
3 phases
Phase One - Designing a New Data & Email Architecture
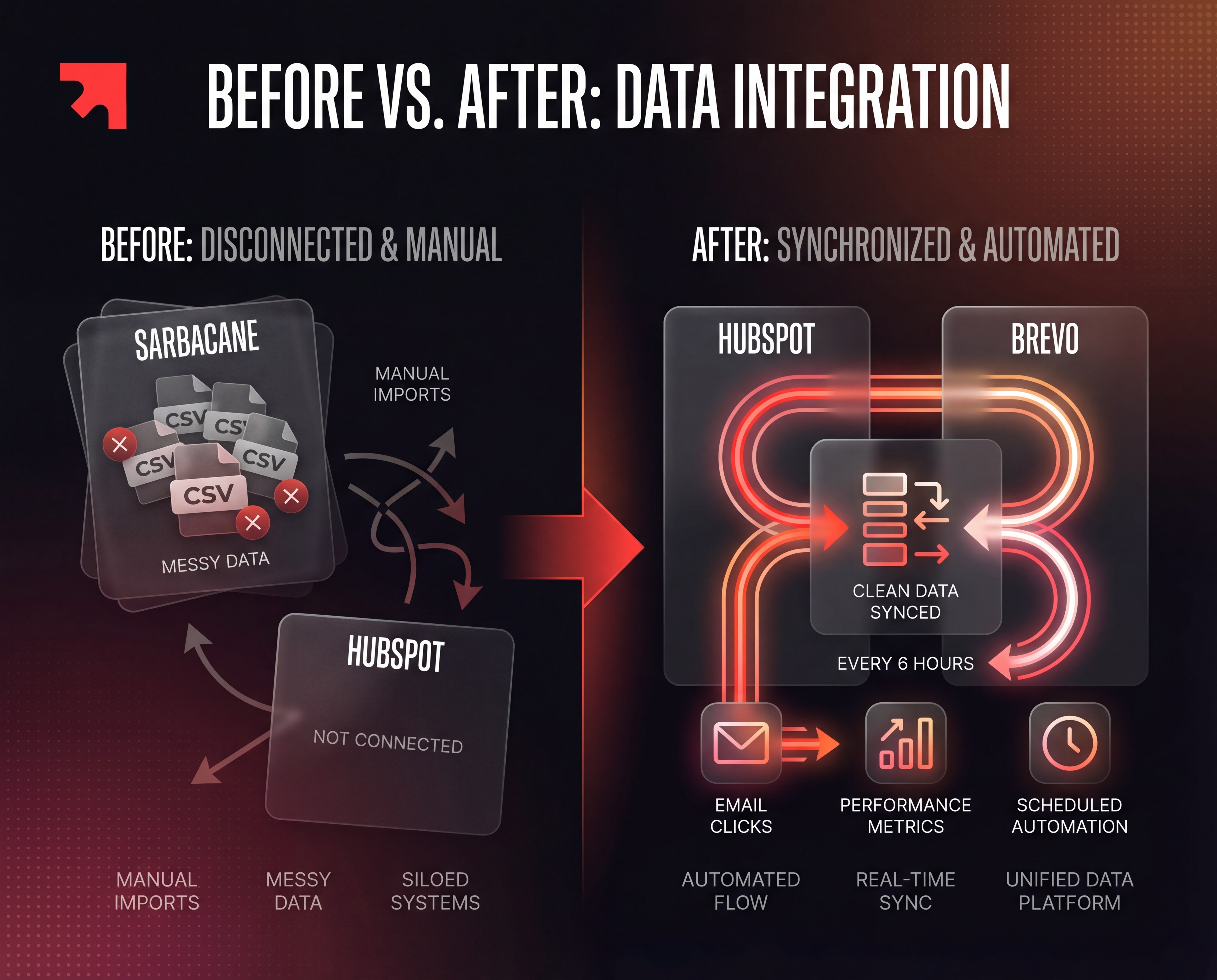
Objective: turn messy, flat lists into a clean, structured, relational data model the CRM can actually use, and build a sending setup that protects TGV Lyria’s domain reputation.
From flat files to a controlled staging area
Rather than importing everything into HubSpot and hoping for the best, Cashmyrr introduced a staging database using SQL and MongoDB. Data from CSV/Excel files (FR, DE, EN) was consolidated there first. MongoDB aggregation pipelines (such as $project, $unionWith, $lookup) were used to:
normalise fields: turn all opt-ins into a single boolean "true/false" standardise dates
dynamically exclude emails found in dedicated "complaints" or "npai" collections
Remove all phone numbers in email (0606060606@icloud.com)/invalid format emails that could cause deliverability issues
Only once data had passed through this staging and cleaning layer did it move on to HubSpot.
Smart upserts instead of blind imports
To avoid overwriting good data already present in HubSpot, Cashmyrr built an n8n automation workflow acting as an ingestion controller:
The workflow queries HubSpot in batches via API.
For each email, it first checks whether the contact already exists.
It then updates only missing fields or creates a new contact if needed.
The result: TGV Lyria ends up with a consistent, enriched CRM not an overwritten one.
Protecting domain reputation with a dedicated subdomain
Bulk campaigns were also re-anchored on a safer email infrastructure:
Instead of sending from the main domain, Cashmyrr configured a dedicated subdomain: newsletter.lyria.com
Strong authentication (DKIM, SPF, DMARC) was set up to maximise inbox placement.
Native bi-directional sync ensured that hard bounces and unsubscribes from Brevo flowed back into HubSpot approximately every six hours, keeping contact statuses aligned.
Also configured workflows in Brevo that remove hard/soft-bounce to avoid issues in first deliveries
Phase Two - Cleaning the Legacy Database
Once the new architecture was in place, the next issue was data quality inside HubSpot itself.
Years of imports had created a “fuzzy duplicate” problem that simple email-based deduplication couldn’t solve:
jean.dupont@company.com vs j.dupont@company.fr
Typos or alternate spellings of first/last names
Mixed B2B / B2C profiles
With B2B and B2C data intermingled, the deduplication work required cleaning both populations and applying arbitration rules then, separately, restructuring B2B company accounts.
Clustering contacts before deciding what to merge
Cashmyrr started with deterministic clustering grouping potential duplicates based on different keys:
Exact email address
“Domain + last name”
“Phone number + last name”
This created focused groups of contacts likely to refer to the same person or company, without merging anything yet.
Adding AI to handle the “grey zone”
For ambiguous pairs, those with an initial similarity between 0.60 and 0.84 Cashmyrr used OpenAIGPT to analyse semantic similarity:
Does this look like a nickname vs full name?
Are there typical typos between the two strings?
Are first and last names swapped or abbreviated?
GPT produced a confidence score, and only pairs reaching ≥ 0.85 were merged automatically. Everything below remained available for manual review.
“Smart” merge rules instead of destructive merges
When a merge did happen, it followed precise, field-by-field rules:
keep the most valid email
keep the most advanced lifecycle stage (Customer > Opportunity > Lead)
preserve the existing owner when it made sense
This allowed TGV Lyria to reduce noise in the database without losing valuable information.
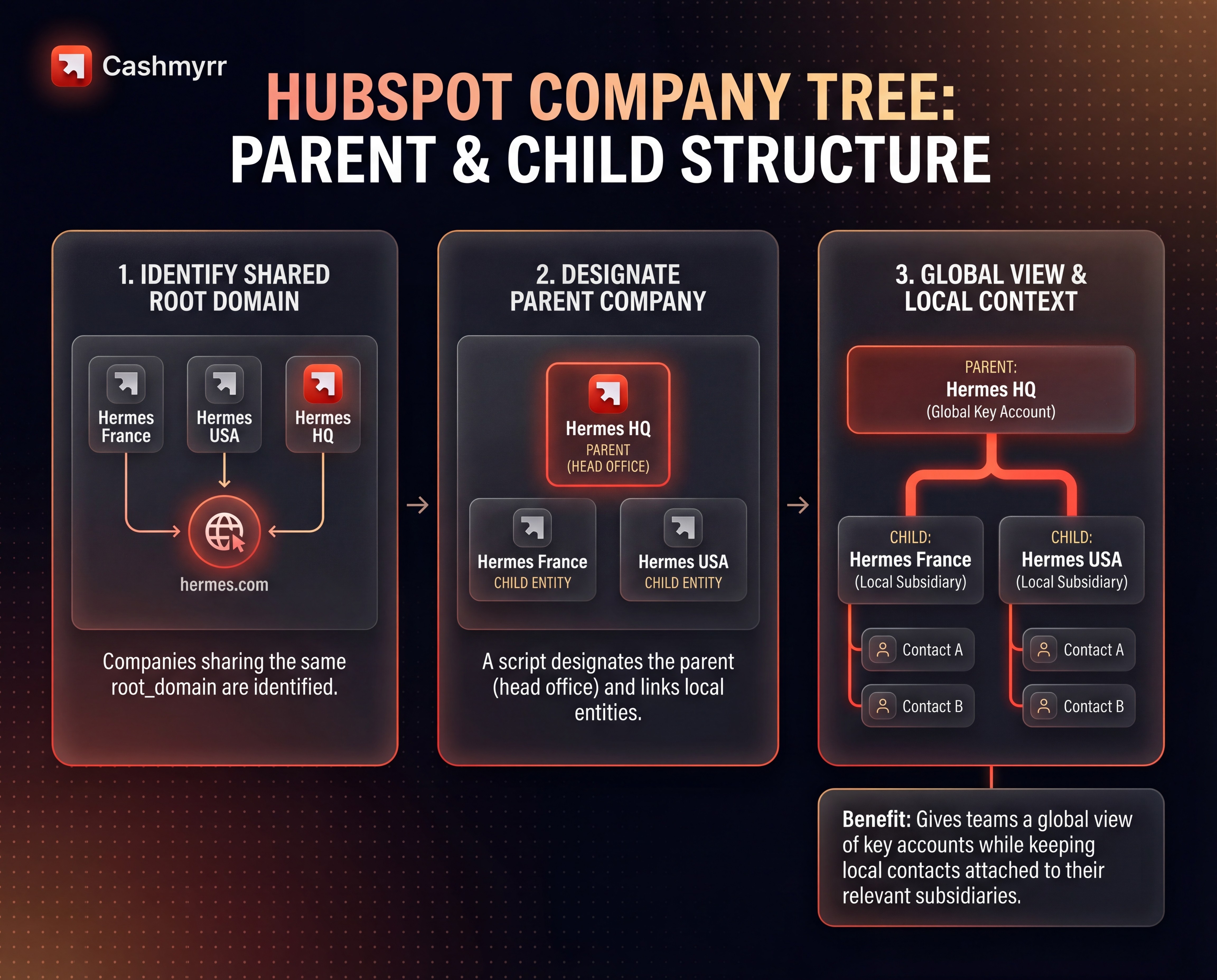
Restructuring B2B accounts with parent / child companies
For B2B data, Cashmyrr also introduced a Parent / Child model:
Companies sharing the same root_domain (for example hermes.com) were identified.
A script then designated a “parent” company (often the head office) and linked local entities as child companies.
This gives teams a global view of key accounts while keeping local contacts attached to their relevant subsidiaries.
Phase Three - Fixing the Data at the Source
Cleaning legacy data is one thing. Stopping pollution at the source is what makes it sustainable.
The problem: uncontrolled web inputs
Several “home-made” sources were injecting low-quality data directly into HubSpot:
Pure HTML forms
Search bars and on-site features that could create contacts automatically
This led to thousands of “Organic Leads” with almost no usable information or consent. At the same time, marketing cookies were being set before users had accepted them, raising GDPR concerns.
Locking down HubSpot’s open doors
Cashmyrr tackled this in two moves:
API lockdown
The HubSpot feature that allows contact creation from “Non-HubSpot Forms” was disabled.
Only controlled, intentional touchpoints could now create new contacts.
Conditional tracking via CookieFirst
The Google Tag Manager integration was rewritten.
The HubSpot tracking script and the hubspotutk cookie (which ties web visits to CRM contacts) now only fire after explicit consent via the CookieFirst CMP.
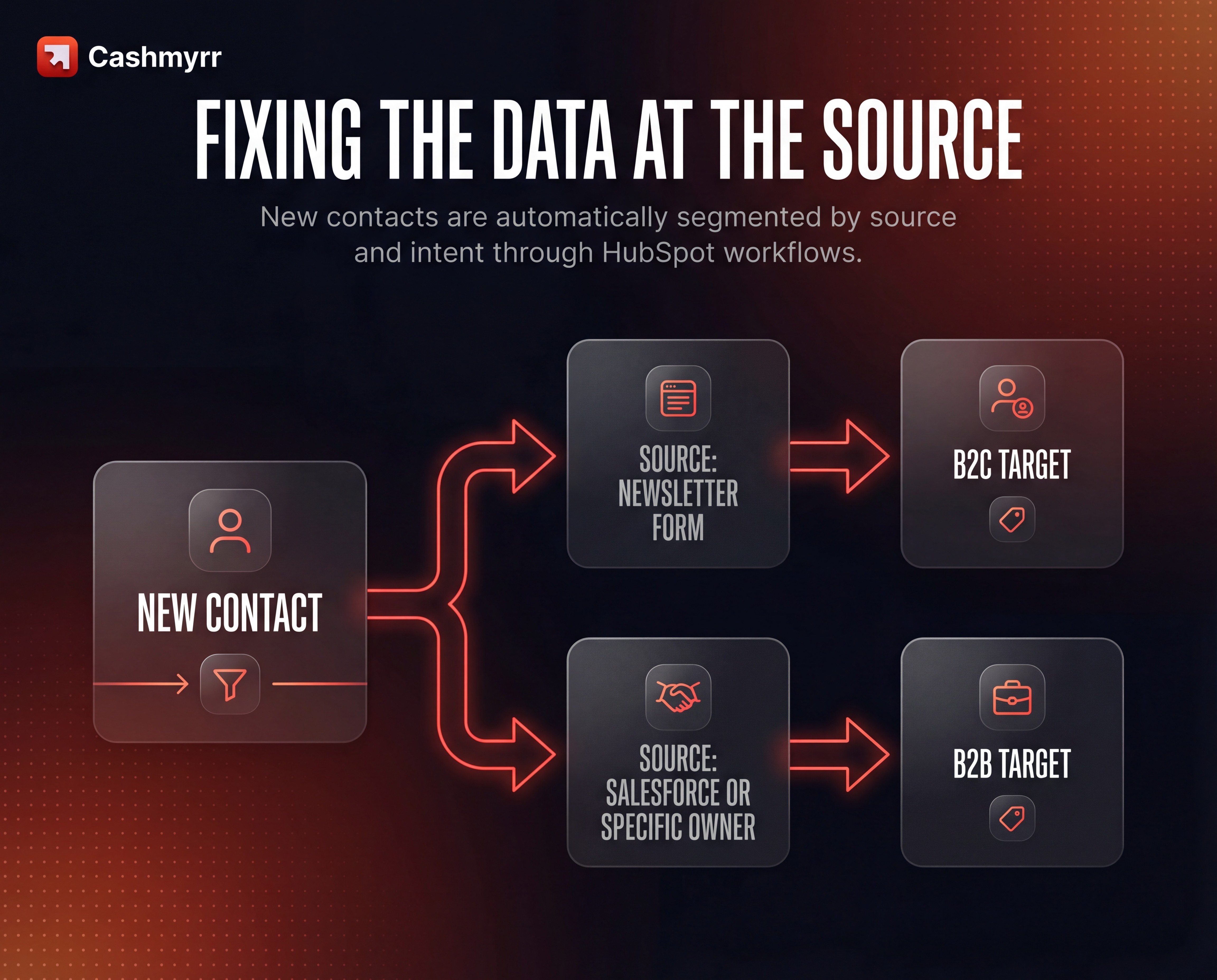
Automatic segmentation from day one
New contacts are automatically segmented by source and intent through HubSpot workflows:
If the source is “Newsletter form” → the contact is tagged as a B2C target
If the source is Salesforce or a specific Owner → the contact is tagged as a B2B target
This means cleaner reporting and more relevant campaigns from the moment a new contact enters the database.
Documentation as a Strategic Asset
A project like this involves external scripts (n8n, Python/SQL) and a lot of subtle business logic. If it lives only in people’s heads, knowledge loss becomes the main long-term risk.
From day one, Cashmyrr treated documentation as part of the deliverable.
Technical documentation that’s actually usable
The team produced Markdown documentation that describes:
What was done (architecture, workflows, scripts)
How it was done, with:
JSON snippets for key n8n workflows
MongoDB queries and their logic
Any developer coming in later can understand the system without reverse-engineering a black box.
Runbooks for day-to-day operations
To make internal teams autonomous, Cashmyrr also wrote maintenance runbooks, including:
How to check Brevo sync logs
How to handle remaining or new duplicates
These are step-by-step procedures; not theoretical notes.
Clear traceability of decisions
Merge rules and AI thresholds were documented in plain language:
Why email A is kept instead of email B
Why the AI threshold is set at 0.85, not lower
How different lifecycle stages are prioritised
If a data point is ever challenged, teams can trace it back to the underlying algorithm and business rules.
The Foundation We Built for TGV Lyria
By the end of the project, TGV Lyria had:
A clean, structured foundation that can handle high-volume campaigns across three markets and languages thanks to Brevo.
An email stack designed to protect domain reputation, with a dedicated subdomain and strict authentication.
A much lower risk of data pollution, thanks to staging, deduplication, and controlled web inputs.
A B2B data model that surfaces parent/child company relationships and supports key-account views.
Clear documentation and runbooks that make internal teams operationally self-sufficient and resilient to staff changes.
All of this was delivered without interrupting campaigns, despite the pressure of a strategic commercial push already in the calendar.
